
Resource Loading
Here is an easy quiz.
Two teams are going to race on the same project. One team planned their work for 90% loading (36 hours per week). The other team planned theirs for 70% loading (28 hours per week).
Which team will get done first?
I know, it sounds like a dumb question. Putting more work in the plan each week means the first team will have a shorter schedule. So the first team wins.
Except you’d be wrong...
That’s the problem with this situation. It's completely counterintuitive. But it’s easy to prove with process science, and we have examples all around us we can learn from.
Resource Loading: The facts
Resource loading is factual principle that can’t be ignored, and has a serious detrimental impact on cycle times. Think about it this way... If someone told you there was a performance curve where half of it was horizontal and half of it was vertical, wouldn’t you want to know three things? Which half is good, which half is bad, and which half are you on?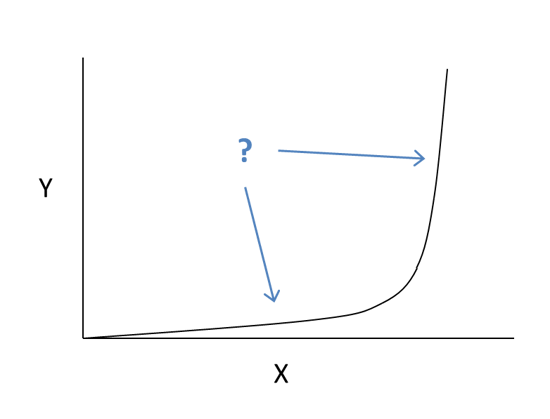 Unfortunately, most companies, departments, teams, and individuals are on the wrong half and don’t realize it.
Unfortunately, most companies, departments, teams, and individuals are on the wrong half and don’t realize it.
In this case, the vertical axis is the cycle time, and the horizontal axis is the “capacity utilization," or how loaded the server is. The math for the curve is fairly complex but understanding the result is very easy.
If you ran the server is at 60% capacity loading, and measured the cycle time, you could plot it on the vertical axis like this...
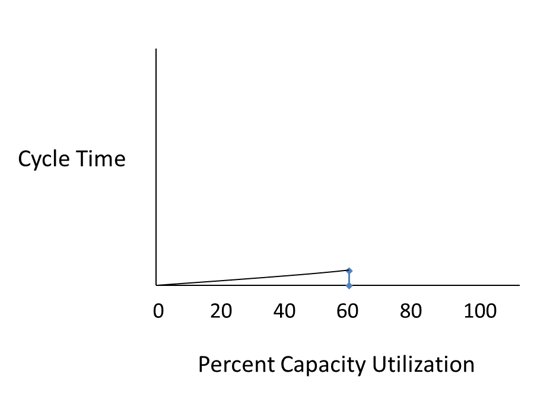
Then, if you increase the loading halfway between where you measured and 100%, the cycle time will double. So increasing loading from 60% to 80% would look like this.
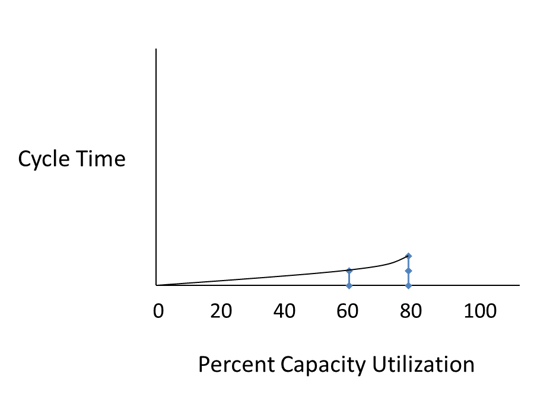
All good so far. But look what happens at 90%, 95%, and 97.5%...
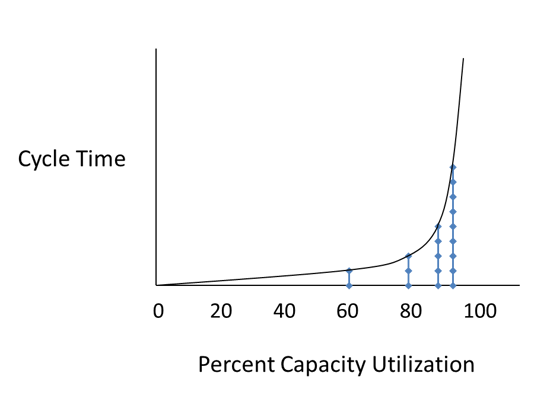
See the problem?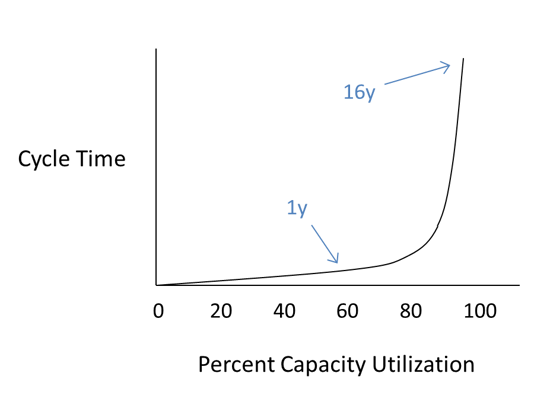
The cycle time at 97.5% is sixteen times what it was when the system was loaded at 60%.
(Do you know how loaded your team is? Book a free 30 minute call with our team and we will help you determine your resource loading.)
Resource Loading: A real-life example
This may seem counterintuitive, but we can see this principle in our everyday lives in rush hour traffic. A trip that takes you twenty minutes when there’s no traffic can easily take three or four times as long during rush hour.
(Ever wonder why they call it “rush” hour? Wouldn’t more people leave at different times if it was called “slow” hour?)
At this level of loading, the system would be ground to a halt and most of the work would be sitting in a giant queue, and the timing of work through our system would look like this...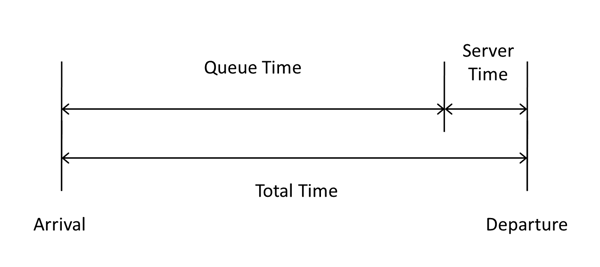
Notice that at a high capacity state, the server may still take the same amount of time to complete the work, so all of the delay is caused by the work sitting idle and waiting.
Another very important (and damaging) thing to understand about queues is they take a lot longer to dissipate than they do to form. Think about the example of where you’re stuck in stop-and-go traffic. You finally get to the front and there’s absolutely nothing there. No accident. Nothing in the highway. Just the front end of a queue. So you step on the gas to get out of there as fast as possible, and even though everyone before you has done the same thing, the queue is still there. That’s because cars are still arriving at a higher rate than they can leave.
So that traffic jam will remain there forever unless the arrival rate slows down until it’s lower than the departure rate for a long enough period of time for the queue to dissipate.
No matter what caused the queue—even someone hitting their brakes for no reason— the only way to get rid of it is to slow down the arrival rate until the queue is gone.
(Fortunately, in our work environments there are other ways to remove a queue which we will discuss in another post sometime.)
Resource Availability
There is another way to explain the effects of resource loading that might be easier to understand, and that’s with the concept of “availability.” Resource loading and availability are essentially the inverse of each other. So when a resource is at a high state of capacity loading, their availability is low.
Below is a graph that shows duration (i.e., cycle time), whose formula is “work” divided by “availability”. Work is the total number of hours to complete a task, and availability is the number of hours per day that the resource can work on it.
The curve shown is for a twelve-hour task. So at six hours of availability per day, it would take two days to get that task done. At four hours of availability it would take three days. And if the person’s availability was only two hours, it will take six days to get this task complete.
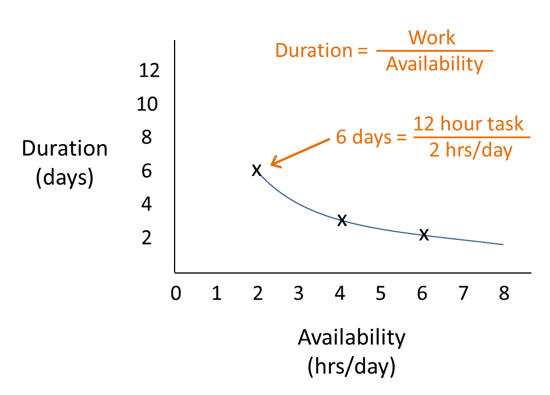
At this point, look what happens if another task comes along and their availability drops by just one hour...
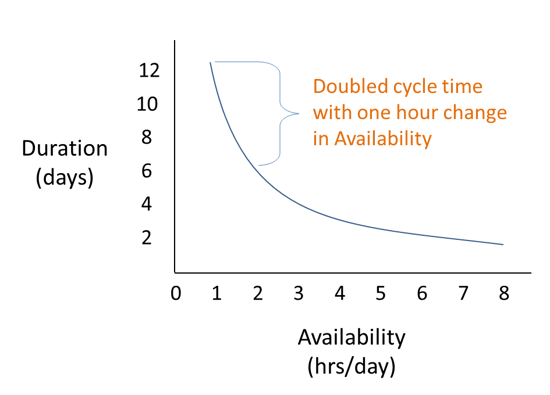
The cycle time of this task just increased by six days due to a one-hour change in availability...!
This is what happens when resources are at high capacity states. Their availability is already low, so small changes on this end of the curve have significant impacts to the cycle time of the work they’re trying to do.
That’s the problem with being on the vertical part of this performance curve. Unfortunately, most companies are and they don’t know it.
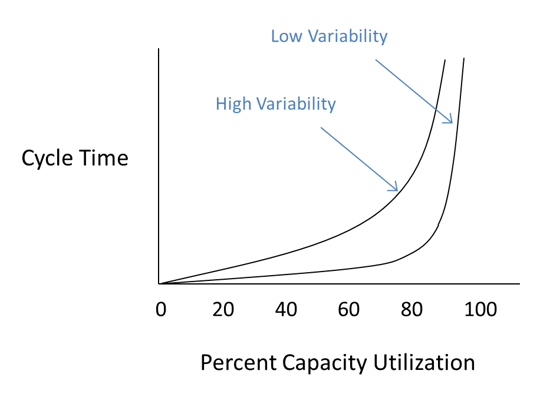
Variability
Another important thing to point out is that this performance curve is for systems with low variability in arrival rates and processing times—like manufacturing. So systems with high variability—like R&D—actually need more spare capacity to maintain short cycle times, or high throughput.
Don’t get me wrong, people will still work forty, or fifty, or sixty hours per week to get their job done. That’s just the way a lot of people are, and it’s sometimes necessary on occasion. But it’s unsustainable over the long term.
But if you are creating plans with that level of loading, you are literally planning to fail.
The Problem
So why do so many companies overload their resources? There are two probable answers. They aren’t aware of this impact (or don’t believe it). But more likely they have no idea how loaded anyone truly is. Do your own test. How difficult is it to determine the actual capacity loading right now (or at any point in the near future) of a department, or team, or individual in your company?
You would think that if the critical importance of this number was truly understood, that this metric would be accurately measured and reported in real time.
Unfortunately, for a lot of companies the best process they have is to assign an “allocation percent” to resources at the beginning of a project and then never look at it again. But even then, they often allocate the resources to 100% and think they will get all of their assigned work done.
Fortunately, there is a solution. We understand the importance of this law of process science, so Playbook monitors the loading of every person on all of their projects, and displays it for every single day on their calendar. So everyone knows at the beginning of every day if the work they have is even possible to get done.
Besides making the project milestone dates a lot more accurate, this has a great benefit to morale as well.
(Do you know how loaded your team is? Book a free 30 minute call with our team and we will help you determine your resource loading.)
Some additional thoughts on Resource Loading
It’s important to know that even if you don’t overload your resources, that queues can still form as a result of large batch transfers. (“Queues and batches” are very closely related and we’ll cover them in a different post.) Large batches automatically create high capacity states. So if a server is sitting idle, and suddenly receives five days of work, that server will be at a high capacity state until that work is done.
But it’s important to recognize that there’s a difference between “working at 100%” and “planning work at 100%.” A high capacity state due to a large batch transfer is a temporary thing, but a high capacity state because of the level of loading used in the plan is a guarantee that your project will be late.
One of my favorite examples of someone who really understood this had just been promoted from Senior Project Manager to Director of Product Development. He asked everyone in his department to list all of the projects they were working on, and when he combined the answers he figured out there were eighteen active projects. So he told everyone that sixteen of them were immediately cancelled and everyone could only work on the two remaining ones.
A couple of months later, both of those projects were done and everyone was shocked. He kept doing this and it wasn't long until his company took notice of his “ability to deliver” and two years later he was VP of a product line. And eighteen months after that he was VP of Operations. So he went from Senior Project Manager to VP of Ops in three and a half years. Obviously he was good at a lot of other things, but he clearly knew how damaging it was to overload his people. So please, etch this in stone and hang it over your desk.
“You can’t get more done faster by adding work to a system. You can only go faster when there is spare capacity.”
Footnotes
For those of you with deeper knowledge of queueing theory, you might have noticed that I replaced “queue size” with “cycle time” on the vertical axis of the capacity loading graphs. This is because for a FIFO system, cycle time and queue size are a linear conversion. However, it may not be what we do in real life. It’s very important to have a prioritization system for the queue and pull the most important work out first. If you do, the detrimental impact of the queue can be reduced significantly. In fact, when you really understand what Playbook does...
...it literally prioritizes the work in every queue so that every individual is always working on the most important task they could be.
This is an extremely powerful concept that allows companies to accelerate projects long before they’ve had time to work on the resource loading.
If you’d like to see other ways that Playbook can accelerate your projects, request a demo here...
