
Early Learning in Hardware Development
This series is a comprehensive review of Agile and how to apply Agile to hardware product development. We look at which Agile Principles work in hardware, which don't and why, and explore best Agile practices for hardware product development.
This post is a continuation of Part 5 in this series. If you haven’t yet read it yet, please do.
In this post, we see how to optimize Hardware Product Development systems and measure progress in our projects by focusing on project risk and burning it down as quickly as possible using a working product.
We agree. Hardware product development is different than software! So when we apply Agile principles, we need a different approach.
Small batch vs. large batch in early learning
We concluded that our optimal approach to hardware product development and Design-Build-Test (DBT) cycles differs from the optimal approach in software due to our component procurement times and higher level of integration. We saw a graphic representation supporting our intuition that short sprints with a working product at the end don’t typically work for hardware product development.
We also discussed that the greatest value of a working product is revenue and/or getting feedback from users outside the engineering team.
The Lean Startup approach to Early Learning
Lean Startup, by Eric Reis, introduced the idea of a Minimum Viable Product. However, as Eric points out, an MVP is not necessarily always the best approach or only approach to receiving early feedback.
Brochures, web pages, and other means may suffice long before we have written a single line of code or built anything that technically ‘works’. By doing so, we can determine whether it is even worth trying to build the MVP we have in mind.
For hardware development teams, some of these techniques work and some don’t, depending on the situation. However, we can still achieve similar feedback, weeks or months or even years earlier, by taking a similar approach of not waiting for the product to be "working" before we learn from outside of the engineering team.
One key to this approach is recognizing that our physical prototypes (physical mockups) or something very similar can produce the valuable feedback we need earlier if we can get them into the hands of downstream people (customers, marketing, sales, etc.). Even if the product is not fit for sale we can get good value from the feedback that tells us if we are on the wrong track.
For example, consider an innovative new car design. If one of our new requirements is a cool new design for how the door opens and closes (like a DeLorean, but different) we don’t really need the new car to 'work' before we get good feedback. We only need the door, some basic fenders attached to a basic frame, seats, and a steering wheel.
We probably need a wall next to it to simulate our garage, and maybe another car to simulate a parking lot, and we need some bags of groceries, a computer bag, and whatever else people commonly carry with them into a car.
Then, after we try it ourselves and work out any major kinks we can share it with some potential customers. We get some moms and kids, some tall people, some elderly people, and any other demographic that fits our customer profile and can give us good feedback. We get them to try it and tell us what they don’t really like, gaining valuable information much earlier by not waiting until the car is built and running. We debatch the valuable information about the door requirements from the rest of the car, as much as we can quickly.
Alternatively we could retrofit our new door onto some existing vehicles and have some customers drive them for a week or two. This would better represent the real life (downstream) conditions and expose more issues such as leaks or rattles at highway speeds. The more ‘real life’ our test is the better, because we discover unknown-unknowns earlier from the people who do things we didn’t expect. A retrofitted door on a different vehicle might not be a ‘working product’ per se, but it sure can deliver valuable information.
De-batching value for early learning
We de-batch value when we separate two or more valuable things so that at least one of them can be delivered earlier. Often, but not always, we complete both things earlier by de-batching them. Earlier value is higher value, so this improves our overall performance.
Agile software teams de-batch value by breaking their requirements and risks into small pieces and carrying each piece all the way to the ‘value bank’ (working product) finish line before starting on the next piece.
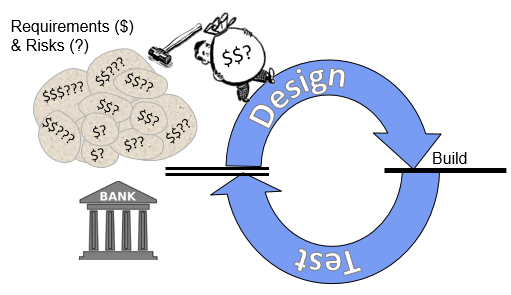
Figure 1 - The DBT race in software
The amount of work is how heavy the bag is and determines how long it takes to run each section of the software track. We reduce the work load and go proportionally faster by carrying fewer requirements. e.g. we can meet thirty requirements in thirty days or three requirements in three days.
We go even faster by focusing on fewer requirements because we add less work in switching costs and find and fix bugs much faster. e.g. three requirements would take just two days. Because it would typically take more time to build a usable mockup as it would to build the actual feature into the actual product, we just build the feature. And, in today’s Agile teams, there is little to no wait time on the track.
These characteristics combine to make it optimal in a software development system to carry very small pieces to the end successively (in series). This minimizes the amount of time it takes to realize each piece of value, which maximizes value overall.
In Hardware, Batches Contain Procurement Times
However in most hardware teams, even when we are careful to reduce our lead times as much as possible, most batches still contain some procurement time which opens up some availability to other activities. We get to set our bag of value on a conveyor belt that takes it through procurement and go back and pick up another bag. In fact, waiting too long at the end of the belt for the parts to arrive is a waste of valuable time.
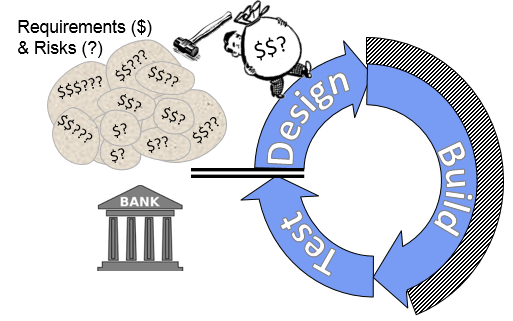
Figure 2 - The DBT race in Hardware
However, tracking multiple bags through the process is a bit costly and this reduces the value of de-batching them. Also, the high level of integration in our hardware products and the cost of our components further increase the cost of de-batching.
We can easily have parts on the procurement conveyor belt when we arrive with a new bag containing modifications to the same parts. In addition, our ability to represent the actual product in our physical prototypes is limited, so we will miss some of the issues we would find if we had, for example, the actual new car door on the actual new car. This decreases the value of de-batching even more.
These costs are clear and somewhat unavoidable, and they are the forces which drive us to the large batch, slow, delayed feedback mode of traditional product development. However, we can minimize them and get into a much faster, leaner mode.
In hardware, we are typically best-off reducing DBT batch size as much as we can in small, risky areas, and doing a few of them in parallel. One key is to not do too many at the same time, because that is essentially the big-batch (slow) development process we have today. We must be at the end of the conveyor belt ready to pick up the biggest value when it gets there.
De-batching learning is de-batching value
When we look at a project risk and the burn-down graph associated with each risk, it takes the same shape as the errors graphs presented in the last post. In fact, there is very little difference between a risk and an error -- especially an undiscovered error. Both are about the impact of the error or risk and eliminating each one (learning) earlier whenever the benefit of doing so outweighs the cost.
Rather than batch our learning and delaying it all until we can put everything together and test it all (e.g. Alpha testing), we are much better off debatching the questions, answering them separately, and then merging the answers into an integrated ‘working product’ when we have them.

Figure 3 - The value of de-batching learning.
In the first image above we have three risks and are burning them independently. The graph shows the per-risk burn-down with the thick lines indicating procurement and build. The double-lines are where we are incorporating our new knowledge into the product.
In the second graph which shows total risk, we stack the three risks on top of each other. The thick lines on the Batched Learning path again indicate procurement, but now it is delayed until we have designed all three three risky areas into our product and we are ordering parts for all of them at the same time. By the time we receive our parts and start testing (learning) in the batched scenario we have already burned half of our risk in the de-batched scenario.
Using Kanban to drive sprints
Maybe there are some cases where sprints which include a working product can work in hardware development. But is it really what we should strive for? Extending the sprint to make it long enough for a complete DBT cycle just encourages us to multi-task and batch up our tests which simply delays some of it.
Instead a Kanban (one-piece-flow) approach works best, where focus is typically put toward the biggest risk until we reach the point where we are waiting for parts. Then we focus on the next highest risk until those parts arrive.
Sometimes our procurement times cause the optimal sequence to go a little out-of-order from the risk exposure, and sometimes we can 'kill two birds with one stone' so to speak, but highest risk to lowest is the general rule.
To drive this activity smoothly, planning at a regular cadence (like sprints promote) is still valuable, but we use ‘definition of done’ for each task we think we can achieve in a sprint rather than working product. For example, the picture above depicts a situation where ‘done’ for sprint 1 consists of ordering the parts we need for risk 1 and risk 2, and maybe some work completed on risk 3.
Other keys to early learning in hardware development
There are many other important pieces to doing all of this, but this has become a long enough post already, so I will simply mention some of them in list form, and table them for later discussions:
- We can only de-batch our learning and achieve a higher risk burn rate if we have good, healthy risk identification and management processes. We need to find the areas likely to cause problems and learn in those areas earlier.
- Certainly minimizing our procurement times is critical to faster learning, but there is a tradeoff between the getting something quickly and getting something that will produce a good test and good information. Albert Einstein is credited with saying 'Everything must be made as simple as possible, but no simpler'. We must also procure our components as quickly as possible and no quicker.
- In parallel with risk-focused DBT cycles, it is important to have a ‘core product’ we continually build and test, e.g., have the basics of our car assembled (frame, engine, etc.) so we can integrate and test some things to identify our integration issues and the unknown-unknowns we can’t find until the pieces are integrated. We integrate when the risk of integrating is less than the risk of NOT integrating.
- All of this requires careful consideration of our product architecture and sufficient modularity in the high-risk areas. Modularity helps us develop more in parallel, and it enables later and faster changes. However it also increases unit cost and degrades performance. Only with careful consideration can we get fast development, low cost, and high performance.
- Even though it costs us a little more, we will need to buy some parts for one test only to buy different versions of the same parts, soon after, for a different test. Very often, the extra part cost is more than paid for by the earlier learning associated with the first test.
Measuring progress in hardware development
Agile’s Seventh Principle: Working product is the primary measure of progress.
In hardware, our working product -- especially early in development -- is spread across multiple, independently progressing project risks and the mockups and tests which provide us value. This makes it a little more difficult to measure, but it is still measurable. We can measure it via an overall risk burn-down score, which is the sum of the scores of our individual project risks.

Figure 4: Project Risk Burn-down Chart
As long as we are true to the process, and we have clear definition of done for each risk (definition of ‘burned down’ from High to Medium, and Medium to Low, etc.) this measurement of progress works very well. In fact, burning project risk is what product development is all about, and maximizing our risk burn rate is how we complete projects and create profits the fastest way possible.
Continue with us to the final post in this series, where we will wrap up the remaining Agile principles. Fortunately, the other principles largely apply to hardware development. Stay tuned...
----
At Playbook we make some pretty significant claims regarding Playbook’s ability to shorten development cycles. In Part 1 of our demo video we show you two paradigm shifting concepts around what causes late projects.

After watching Part 1, have a look at Part 2 to see how Playbook uniquely solves for these problems. Alternatively you can download the Applying Agile to Hardware eBook.

Related articles
Agile Development
Applying Agile Values to Hardware Development
Agile Principle 1: Early and Continuous Delivery of Value
Agile Principle 2: Welcoming changing requirements
Making Hardware Development More Agile
Early Learning in Hardware Development
Agile Principles 4 - 12 to Hardware Development
Guide to Agile Product Development
